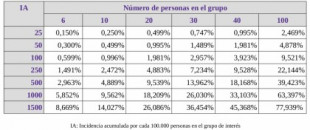
Los índices de incidencia acumulada (IA) a 14 días se usan por las autoridades para reflejar qué porcentaje de la población ha dado positivo en el contexto de la actual pandemia. El hecho de que se den en casos por cien mil habitantes y lo poco intuitivo de cómo funciona la estadística en este caso (similar a la paradoja del cumpleaños) hace que posiblemente se infravalore la probabilidad de tener a algún positivo en el entorno cercano. Por eso, os presento una tabla para cuantificar la probabilidad (en tanto por ciento, fácilmente entendible).




Comentarios
Especialmente importante para empresas que, pudiendo hacer teletrabajo, no lo hacen.
#5 es que falta poner en el modelo la variable:
Jefazo intermedio totalmente prescindible que es solo un patético lame botas con síndrome de trepa, busca bono, que se ha dado cuenta que el teletrabajo lo expone como realmente es: una garrapata de la organización. Y busca afanosamente volver al trabajo presencial para que no lo vean como el parásito que es y seguir engañando con sus reuniones "productivas", sus animaciones de Powerpoint y el nuevo gráfico estadístico que conoció en Excel.
#16 no veo que se pueda derivar tan fácilmente del artículo lo que dices.
Por ejemplo tu razonamiento ignora el número de reuniones de cada tamaño y que en reuniones muy numerosas si hay un contagioso es poco probable que interactúe con un grupo amplio.
Como finde #5 es más relevante para que los jefes hagan sus cuentas y sepan cómo va cambiando la probabilidad de tener a toda la plantilla en cuarentena por hacerles ir a la oficina incluso con la posibilidad de teletrabajar.
#14 gracias por repetir mis palabras. Como veo que no queda claro lo explico de nuevo:
- No tiene sentido contar los positivos como posibles contactos por estos están confinados y por lo tanto las posibilidades se reducen a que se salte la cuarentena.
- No tiene sentido sacar las probabilidades solo con los positivos porque la mayoría de infectados no son detectados.
Para que estas cuentas tuviesen sentido habría que hacerlas con el número de infectados no detectados + número de positivos que se saltan la cuarentena, lo cual obviamente es imposible, al menos por la parte de no detectados.
Lo que si que se podría hacer son estimaciones del número de infectados no detectados respecto a la incidencia acumulada y con esos datos sacar la binomial. Y eso tendría tanto sentido como exactitud tengan esas estimaciones.
#15 pero esos detectados han pasado por un periodo de ser contagiadores y no estar detectados... por lo que no los puedes excluir, así que lo único que hay que contar en que proporción hay asintomáticos y como solo se puede saber si hay asintomáticos detectándolos, pues está bien coger el número aproximado que nos dan y no se podría hacer de otra manera.
No se si me he explicado bien.
#15
- No tiene sentido sacar las probabilidades solo con los positivos porque la mayoría de infectados no son detectados.
¿Puedes demostrar la última afirmación?
#39 busca en Google "estudio seroprevalencia Covid" y comparar las cifras del estudio con las cifras oficiales de infectados.
#40 Hay consenso en que la mayoría de casos se escaparon del radar en la primera ola. Pero no hay pruebas que sea así ahora mismo (en la misma escala que en la primera ola, quiero decir).
https://datadista.com/coronavirus/estimacion-diagnostico-segunda-ola-covid19/
Salvo que tú presentes esas pruebas, claro.
#41 yo no tengo que probar nada, primero porque no soy científico y segundo porque ya está probado que la inmensa mayoría de casos son asintomáticos, y sumado a la falta de rastreadores tienes la ecuación perfecta para que se pasen por la alto la inmensa mayoría de los casos.
Te doy un dato que repiten en la TV a diario: en España solo se consiguen rastrear menos del 20% de los casos, es decir, que en más del 80% de los casos no se sabe cono se produjo el contagio.
Y si te quieres informar más te informas por tu cuenta, y sino no me des más la brasa.
#43 Sí, si tienes que probar lo que dices o si no quedas como un cuñao y un troll.
De modo que, como no puedes probarlo, tu argumento se desmorona. La próxima vez documéntate e infórmate mejor.
#44



Claro que si. ¿Ya te has quedado contento? Pues ale, a dormir que es muy tarde.
#45 Antes voy a limpiar un poco mi meneame.... hasta nunca.
Vaya te querías hacer el listo con R y no te salió.
Te he dado la respuesta, velocidad y productividad, basada en trabajar con Mathlab a diario por más de diez años e intentarlo con R varias veces y es que no hay comparación (photoshop vs gimp) .
ya puedes ir a dormir que has aprendido algo nuevo hoy.
Espero que te sirva en un futuro.
#13 No te mates, el señor de las patatas no sólo tiene una actitud nazi con el software libre sino que cuando le llevas las contraria razonadamente te manda al ignore (supongo que para enriquecer el debate ). Para rizar el rizo le mete GNU a todo delante. Creo que a su novia virtual la llama GNU Cari.
Cuando ya llevas tiempo por aquí vas conociendo la fauna. ¡Ánimo!
#19

 positivo por lo de GNU Cari
positivo por lo de GNU Cari
Edit2: que bueno...creo que es que también tengo sueño. De ahí la “carcajada tonta”
#13 Las funciones de R base están compiladas en Fortran, C y C++ y el lenguaje en sí está pensado para operar de forma vectorizada, así que eso de que es lento no te lo compro del todo. Pero para hacerlo funcionar a una velocidad aceptable tienes que cambiar mucho el chip y si vienes de lenguajes más tradicionales (como los anteriores) cuesta mucho hacerte a esa forma de trabajar. Por ejemplo, un error que se suele cometer al empezar a usar R es utilizar bucles for para recorrerte un data frame y hacer alguna operación fila a fila. El problema es que el tiempo de llamada a la función compilada es alto y en un bucle for lo estás multiplicando por el número de iteraciones, mientras que en vectorización sólo haces una única llamada sobre todo el objeto (ya sea data frame, lista o vector).
En cuanto a productividad, también depende mucho del uso que le quieras dar. Creo que Matlab funciona muy bien para cuestiones puramente matemáticas (la librería de procesamiento de imagen también me parece buena) pero para tratamiento de datos y machine learning creo que R es infinitamente superior.
#36 Ejem, soy demasiado vago como para escribir un bucle que multiplique una matriz
En serio tienes razón en ello, pero haz una simple prueba, generar una matriz aleatoria de 1000 X 1000 y busca su inversa, la diferencia puede estar tranquilamente en 2X.
Sí, yo lo estaba enfocando puramente matemático, si añades en la ecuación ML, es otro debate, aquí no opino por que nunca he usado R y tal vez le
debería dar una oportunidad, en mi trabajo normalmente prototipamos los modelos en MathLab y los implementamos en ScyPY directamente o algún framework tipo Keras, PyTorch o Scikit-learn según llueva.
Donde R si es el rey indiscutible es en minería de datos, aquí creo que nadie lo va a poder negar, ahora mismo el es estandard a mucha distancia de cualquier otro.
#38 hace ya tiempo que no implemento algoritmos y me bajo tanto al barro, así que no tenía presente que pudiera tardar tanto en hacer esa operación. En mi portátil (un MacBook con algunos años encima) tarda de media un poquito más de dos segundos (con un simple solve). No sé cuánto puede tardar en Matlab, pero para ser matrices tan pequeñas a mi al menos me parece mucho.
Porqué utilizar Matlab cuando puedes utilizar GNU R
#7 Matlab es más fácil de aprender muchísimo más rápido que R en general, y el entorno es simplemente más productivo, los matemáticos lo preferimos por eso como herramienta base. ¿He dicho ya que R es leeento?
R para estadística y análisis está bien (para los que no puedan pagar la licencia, no quieran aprender Python + Numpy o todavía no conozcan la joya de GNU que es Octave)
#11
Gracias por tu aporte basado en nada.
#11 Octave está bien, pero la GUI deja mucho que desear...
#11 Matlab es más fácil de aprender y más rápido, efectivamente, pero yo no diría que "los matemáticos lo preferimos por eso como herramienta base". Yo también soy matemático, y juraría que R está mucho más extendido que Matlab entre matemáticos, incluso como herramienta de propósito general
#28 La verdad es que hay campos en los que se usa más R, y otros matlab. Y la única razón que veo para ello es por inercia y el número de herramientas desarrollada para un campo en concreto.
#28 #31 Seguramente también sea un tema generacional. Si lo aprendiste mientras estaba en su punto álgido.
#7 Yo uso la calculadora: P = 1-(1- casos por cien mil /100000)^(tamaño del grupo) 😎
#17 Dado que las IA (en tanto por uno) se mantienen mucho menores que 1, puedes desarrollar en serie y quedarte con la aproximación de primer orden que da poco error.
Esto es, tan sencillo como IA*(tamaño del grupo)
#7 Yo tengo una relación de amor-odio con R. En este caso hubiese usado R.
Y eso esto en un solo grupo en un modelo matemático. En una situación real, en que mantenemos contactos repetidos con diferentes grupos a lo largo del tiempo, los números son para asustarse.
#1 Son un poco menores, porque hay gente que ya se ha contagiado y son inmunes. Pero si, el crecimiento es muy rápido.
#1 la realidad es mucho más complicada que una simple distribución estadística. Para empezar es absurdo usar la incidencia acumulada por infinidad de motivos, unos hacen que en realidad sea más probable tener contacto con un positivo y otros que sea más difícil. Por ejemplo:
- La mayoría de infectados son asintomáticos.
- La mayoría de los positivos están encerrados en casa o en el hospital.
Vamos, que estos datos no sirven para nada más allá de un buen ejemplo para aprender o rememorar estadística básica.
#10 Si la mayoría de infectados son asintomáticos, no saben que son positivos y no están en casa ni en el hospital.
#10 #24 creo que la intención del artículo es hacer una aproximación para que la gente entienda que si dicen por la tele "hay 500 casos de IA por cada 100.000 habitantes " no piensen "ah, eso es un 0,5% , es más probable que me caiga una maceta en la cabeza"
#10 Esos asintomáticos pueden contagiar por lo que para el caso que se comenta no influye. Aparte muchos de esos no están diagnosticados por lo que no se cuentan en la incidencia acumulada.
Son muchos aspectos en los que se simplifica, pero el artículo me ha parecido interesante porque sirve para recalcar que en el caso de reuniones sociales de muchas personas la probabilidad se dispara. Mucha gente supone que si la incidencia es de 500 entre 100000 (0,5%), en una reunión de 20 personas la posibilidad de contagio sería mínima y esto no es así.
#1 En parte me sumo a #10. Esto es un modelo, la realidad será diferente, no sé si para mejor o para peor, eso dependerá ya de circunstancias concretas. Yo creo que el meneo es útil para despejar sesgos, podemos debatir muchas cosas, pero por como funciona la distribución es claro que el riesgo aumenta rápidamente en grupos grandes.
Uffffff... La lógica de este cálculo tiene más "peros" que agujeros un colador, no sé por donde empezar...
Lo de la distribución binomial me parece estupendo, és un tema de estadística puro y duro. Lo que me parece terrible es usar la incidencia acumulada a 14 días como base para el cálculo. Ese número te dice cuantos casos se han detectado en los últimos 14 días, se supone que la inmensa mayoría de esos casos van a quedarse en casa haciendo cuarentena, no van a ir paseandose por ahí ni asistiendo a "coronaparties".
Lo que se tendría que usar como base és la cantidad de personas que, en un determinado instante de tiempo, són positivas y no estén en cuarentena, ya sea por que no lo saben o porqué no les dá la gana. La IA puede considerarse como un buen estimador de los casos activos que presentan síntomas. Asumiendo que la mayoría se quedan en casa cuando dán positivo, sólo habría que contar X/14 (donde X és el promedio de días entre que una persona empieza a ser contagiosa y el test dá positivo). A esos habría que sumar los asíntomaticos y personas que nunca se hacen el test, que según los estudios pueden ser entre el 20% y el 80% de los casos...
Resumiendo, que dependiendo de lo que asumas, la IA habría que multiplicarla por un factor que tanto puede ser 0.2 o 5...
#24 pues eso, te puede servir para estimar el orden de magnitud de la probabilidad, exacto es evidentemente imposible porque haría falta información sobre contagiados que andan «libres», dato que sólo se puede aproximar...
#26 Yo creo que el principal objetivo es dar a conocer el riesgo al que nos exponemos, evidentemente como dices, desde el momento que hablamos de estimación hablamos de un dato aproximado que claramente no es el real y que podrá tener mayor o peor margen de error.
#24 Lo que tu dices, no contradice mi afirmación, porque aunque la IA cambie, o sea un reflejo de hace 14 días, las probabilidades no varían, y mi afirmación no se ve afectada.
Lo que yo digo, es, si con una IA baja, tienes una probabilidad > 2% de pillar en virus con más de 100 personas eso es una probabilidad muy baja. Piénsalo, un 2% significa tirar una moneda (asumiendo que tienes 1/2 que salga cualquiera de las dos caras) y que salga la misma cara 5 veces consecutivas (~3%).... pruéba alguna tanda, intenta sacar 5 veces consecutivas la misma cara, es casi imposible, y es la mejor manera de entender ese número.
Una vez lo hagas, entenderás mi afirmación (que se basa en entender la probabilidad), para una expansión del virus tan explosiva, con esas probabilidades tan bajas para esos números solo hay dos optiones: O suelen haber personas que se reune con grupos enormes de gentes, o mucha gente se reune muy frecuentemente con grupos grandes, no hay otra.
#27 Una pequeña corrección, no dice que tengas 2% de pillar el virus, dice que hay 2% de probabilidades de que haya alguien con el virus.
#35 muy buen punto, pues aun más improbable de pillarlo entonces, gracias!
Una buena ocasión para haber utilizado la aproximación de la distribución binomial por la normal.
#8 Lo que pasa es que la distribución binomial se conoce muy bien y además cualquier distribución se puede aproximar con la binomial. Pero se cometen errores. El libro que has mandado tiene buena pinta, pero hay que dedicarle mucho tiempo.
La binomial no aproxima bien la evolución de una epidemia.
#2 claro que no. Pero sí a lo que se refiere #0
#2 Revisa la literatura
http://courses.washington.edu/b578a/readings/bookchap4.pdf
Vamos, que estas probabilidades dejan claro que si el virus se expande cuando la IA es baja, es única y exclusivamente, por aglomeraciones de bastante más de >100 personas (al haber una probabilidad considerablemente más alta de propagación).